📝个人主页:哈__
期待您的关注

目录
🎈 urlib.request
🔥具体的方法
✈ lxml
🔥xpath的基本语法
1. 基本路径
2. 选择节点
3. 谓语(Predicates)
4. 通配符
5. 选择多个路径
6. 函数
7. 运算符
8. 轴(Axes)
🔥🔥🔥爬取美女图片
1.定期请求头
2.获取页面源码
3.爬取我们需要的图片
一点点小问题
源码如下
使用Python爬虫需要使用以下两个库。
🎈 urlib.request
urllib.request是 Python 标准库中的一个模块,它提供了用于打开和读取 URLs(统一资源定位符)的接口。通过使用这个模块,你可以很容易地发送 HTTP 和 HTTPS 请求,并处理响应。以下是对urllib.request的简要介绍:
urllib.request模块允许你执行以下操作:
- 发送 HTTP/HTTPS 请求:你可以使用
urllib.request.urlopen()函数或urllib.request.Request类与 URL 交互,发送 GET、POST 等请求。- 处理响应:返回的响应对象(通常是
http.client.HTTPResponse的一个实例)包含了服务器的响应,如状态码、响应头和响应体。你可以使用响应对象的方法如read()来读取响应体内容。- 添加请求头:通过创建
urllib.request.Request对象,你可以为请求添加自定义的请求头,如 User-Agent、Referer 等。- 处理异常:
urllib.request模块定义了各种异常,如urllib.error.HTTPError和urllib.error.URLError,以便你能够优雅地处理请求失败和错误情况。- 数据编码:对于 POST 请求,你可能需要将数据编码为适当的格式(如
application/x-www-form-urlencoded或multipart/form-data),urllib.parse模块提供了相关的函数来辅助完成这些任务。- 处理重定向和会话:
urllib.request模块能够自动处理 HTTP 重定向,并且可以通过使用urllib.request.OpenerDirector和处理器(如urllib.request.HTTPCookieProcessor)来管理 HTTP 会话和 cookie。- 使用代理:通过设置环境变量或使用
urllib.request.ProxyHandler,你可以配置urllib.request使用代理服务器发送请求。
以下代码是一个示例
import urllib.request # 定义要请求的 URL url = 'http://example.com' # 发送 GET 请求 with urllib.request.urlopen(url) as response: # 读取响应内容 html = response.read() # 打印响应内容(这里以字符串形式打印,实际可能需要根据需要进行解码) print(html.decode('utf-8'))
🔥具体的方法
urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, *, cafile=None, capath=None, cadefault=False, context=None)
- 功能:打开指定的 URL,并返回一个响应对象。
- 参数:
url:要打开的 URL。data(可选):如果请求需要发送数据(如 POST 请求),则将其指定为字节串。timeout(可选):设置请求的超时时间,以秒为单位。cafile、capath、cadefault(可选):用于 SSL 证书的验证。context(可选):SSL 上下文对象,允许你定制 SSL 设置。- 返回值:一个响应对象,可以使用
.read()、.getcode()、.getheader(name)等方法获取响应内容、状态码和头部信息。
urllib.request.Request(url, data=None, headers={}, method=None, origin_req_host=None, unverifiable=False)
- 功能:创建一个请求对象,该对象可以被
urlopen()或自定义的 opener 使用。- 参数:
url:要请求的 URL。data(可选):POST 请求的数据。headers(可选):一个字典,包含自定义的请求头。method(可选):HTTP 请求方法,如 'GET'、'POST' 等。origin_req_host和unverifiable(可选):通常不需要手动设置。- 返回值:一个
urllib.request.Request对象。
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
url(str): 要下载的文件的 URL。filename(str, optional): 可选参数,指定保存文件的本地路径和文件名。如果未指定,则使用 URL 中最后的路径组件作为文件名,并保存在当前工作目录下。reporthook(callable, optional): 可选参数,一个回调函数,它将在下载过程中被多次调用,并传递三个参数:一个块号(block number)、一个块大小(block size in bytes)、以及文件总大小(total file size in bytes)。这可以用于实现下载进度的报告。data(bytes, optional): 可选参数,如果提供,它应该是一个字节对象,将被发送到服务器作为 POST 请求的数据。这通常用于发送表单数据或上传文件。
urllib.request.install_opener(opener)
- 功能:全局安装一个 opener。此后,
urlopen()将使用这个 opener 发送请求。- 参数:一个实现了
OpenerDirector接口的对象。
urllib.request.build_opener([handler, ...])
- 功能:创建一个 opener 对象,该对象使用提供的处理器(handler)列表来处理请求。
- 参数:一个或多个处理器对象,如
ProxyHandler、HTTPHandler、HTTPSHandler等。- 返回值:一个 opener 对象。
自定义处理器
你可以通过继承
urllib.request.BaseHandler或其子类(如HTTPHandler、HTTPSHandler等)来创建自定义的处理器。这些处理器可以处理请求的不同方面,如代理、cookie、重定向等。
✈ lxml
在Python中,XPath通常与解析HTML或XML文档的库结合使用,例如
lxml或BeautifulSoup。这些库提供了对XPath表达式的支持,使得在HTML/XML文档中查找和提取数据变得简单。下面我将以lxml库为例,介绍Python中XPath的使用。
🔥xpath的基本语法
1. 基本路径
/: 从根节点开始选择。//: 从文档中的任意位置开始选择。.: 选择当前节点。..: 选择当前节点的父节点。
2. 选择节点
nodename: 选取此节点的所有子节点。- @: 选取属性。例如,
@lang会选取名为lang的属性。
3. 谓语(Predicates)
谓语用于查找某个特定的节点或者包含某个指定的值的节点。
[1]: 选择第一个子节点。[last()]: 选择最后一个子节点。[last()-1]: 选择倒数第二个子节点。[position()]: 选择某个位置上的节点。[text()]: 选择包含文本的节点。[attr=value]: 选择属性值等于某个值的节点。例如,[@lang='en']会选择lang属性值为en的节点。
4. 通配符
*: 匹配任何元素节点。@*: 匹配任何属性节点。
5. 选择多个路径
通过在路径表达式中使用
|运算符,可以选择多个路径。
6. 函数
XPath包含超过一百个内建函数,这些函数可用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理以及逻辑比较等。一些常用的函数有:
text(): 获取节点文本。contains(string1, string2): 如果 string1 包含 string2,则返回 true,否则返回 false。starts-with(string1, string2): 如果 string1 以 string2 开头,则返回 true,否则返回 false。last(): 返回当前上下文中节点的最后一个节点的位置。local-name(): 返回当前节点的本地名称。namespace-uri(): 返回当前节点的命名空间URI。name(): 返回当前节点的名称。string(): 将节点或节点集转换为字符串。string-length(): 返回字符串的长度。substring(string, start, length): 返回字符串的子字符串。concat(string1, string2, ...): 连接两个或多个字符串。normalize-space(string): 规范化字符串中的空白字符。
7. 运算符
XPath 支持一系列运算符,如:
or、and:逻辑运算符。=、!=、<、>、<=、>=:比较运算符。+、-、*、div、mod:算术运算符。
8. 轴(Axes)
XPath 轴可以定义相对于当前节点的节点集。以下是一些常用的轴:
child: 选取当前节点的所有子节点。parent: 选取当前节点的父节点。ancestor: 选取当前节点的所有先辈(父、祖父等)。ancestor-or-self: 选取当前节点及其所有先辈。descendant: 选取当前节点的所有后代(子、孙等)。descendant-or-self: 选取当前节点及其所有后代。following: 选取文档中当前节点的结束标签之后的所有节点。preceding: 选取文档中当前节点的开始标签之前的所有节点。following-sibling: 选取当前节点之后的所有同辈节点。preceding-sibling: 选取当前节点之前的所有同辈节点。self: 选取当前节点。
下边是一个xpath使用的小教程。
from lxml import html # 假设我们有一个HTML字符串 html_string = """ <html> <head> <title>Example Page</title> </head> <body> <div class="content"> <h1>Welcome to the Example Page</h1> <p class="intro">This is an example paragraph.</p> <ul> <li><a href="https://example.com/item1">Item 1</a></li> <li><a href="https://example.com/item2">Item 2</a></li> </ul> </div> </body> </html> """ # 使用lxml的html模块将HTML字符串解析为HTML文档对象 tree = html.fromstring(html_string) # 使用XPath表达式查找标题(title)元素 title = tree.xpath('//title/text()')[0] print(f"Title: {title}") # 使用XPath表达式查找所有链接(a)元素的href属性 links = tree.xpath('//a/@href') for link in links: print(f"Link: {link}") # 使用XPath表达式查找具有特定类的段落(p)元素的内容 intro_text = tree.xpath('//p[@class="intro"]/text()')[0] print(f"Intro text: {intro_text}")
行了不多说了,直接开始我们的主线,爬取美女图片。
🔥🔥🔥爬取美女图片
我要爬取的页面在这里:https://aspx.sc.chinaz.com/query.aspx?keyword=%E7%BE%8E%E5%A5%B3%E5%9B%BE%E7%89%87&issale=&classID=11&navindex=0&page=1
这个链接将会作为我们的url,但并不是固定的,我会把它写成一个动态url,拼接我们要爬取的页码。
1.定期请求头
我们使用爬虫来访问网页的话可能会因为一些请求头部的信息校验过不去而被阻拦,我们定制一个有请求头的request出来。
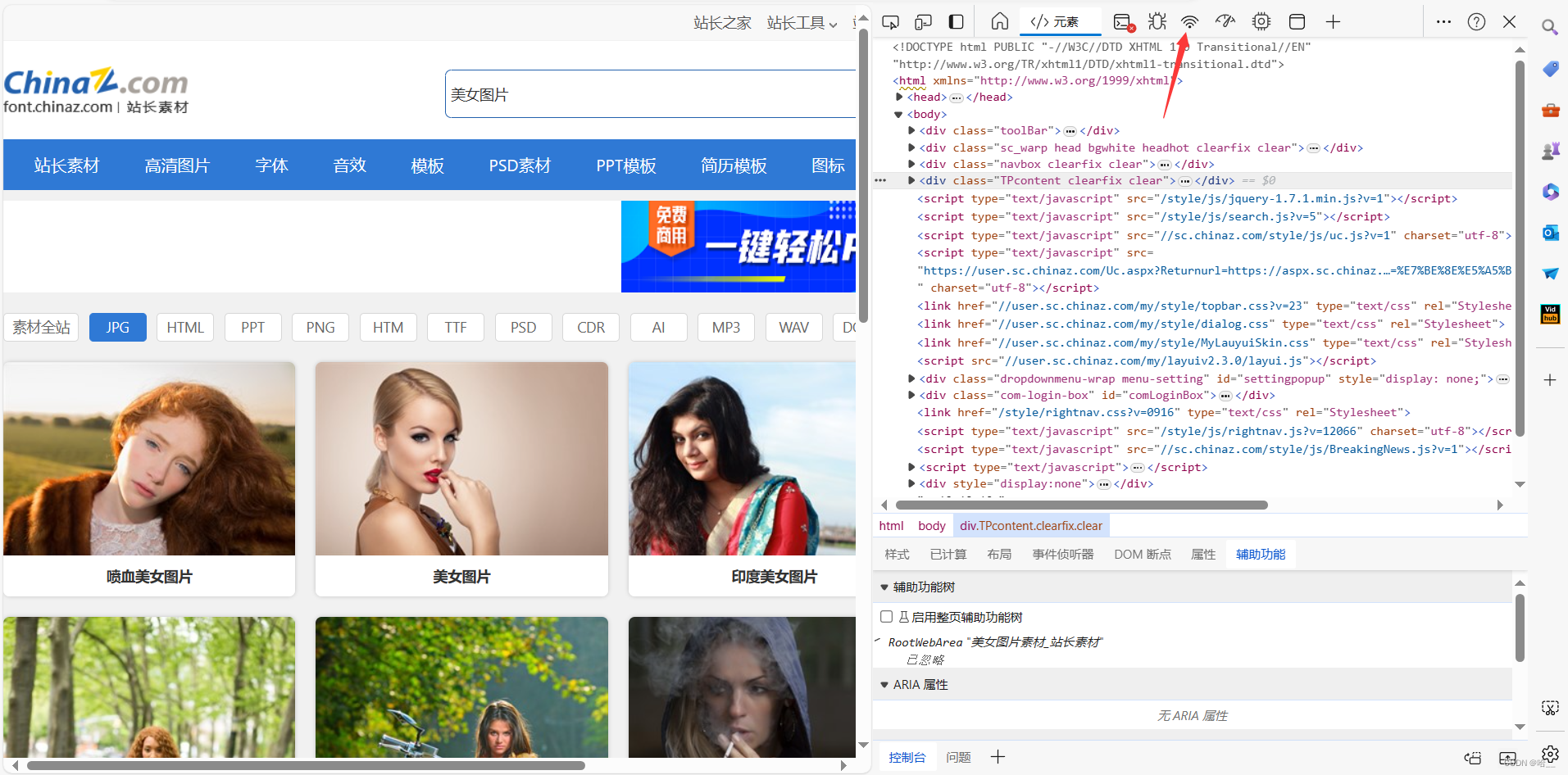
先打开我们要爬取的网页,右键点击检查,之后在弹出的功能栏中找到网络模块。
这时候你点进去大概率会什么都没有,我们刷新页面再看。
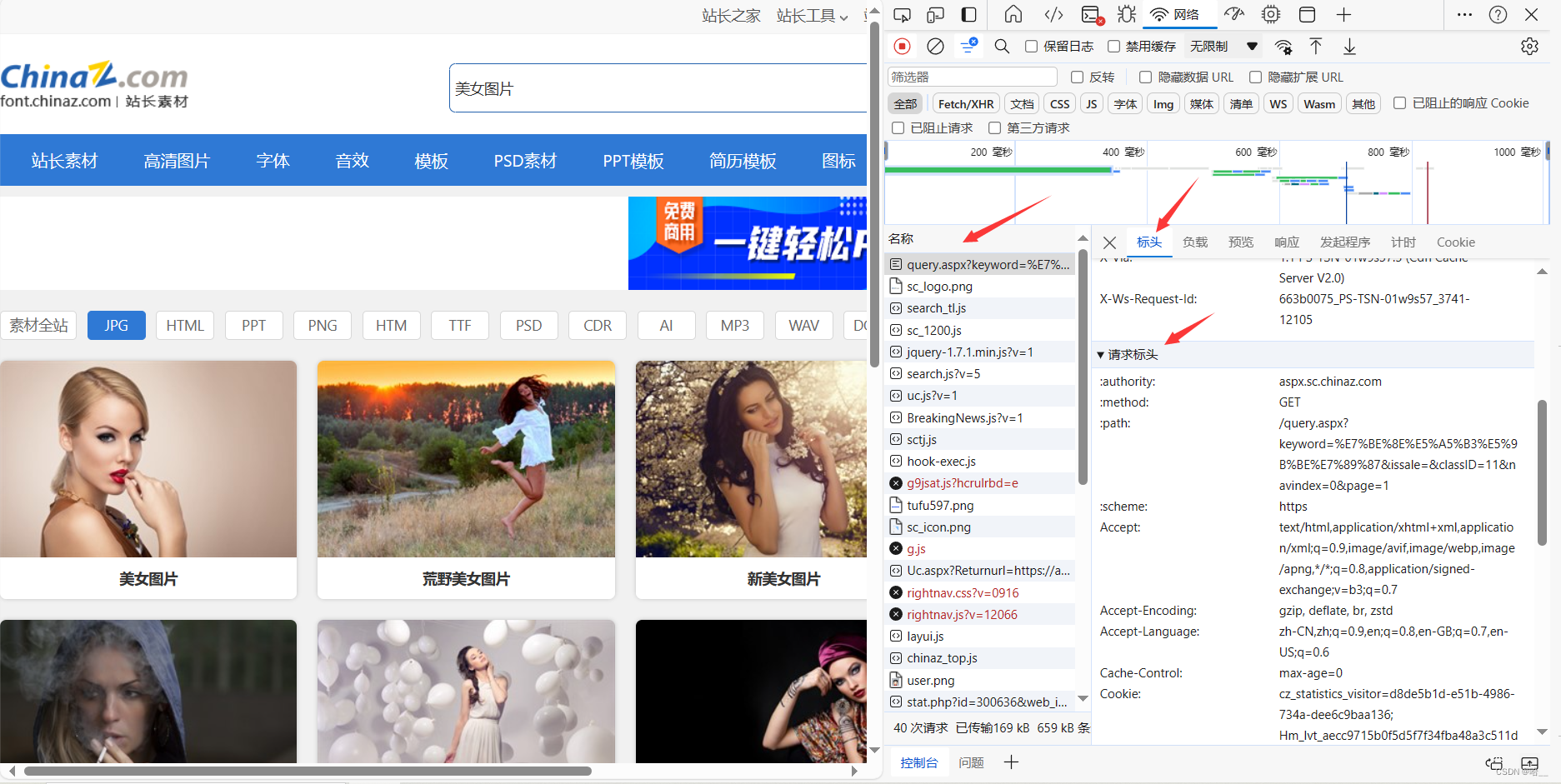
这时就会有很多的网络请求,我们的目的是爬取图片,那我们就要知道这些图片是哪一个网络请求加载出来的,看图中的红色箭头指向的一个请求,这个就请求就是我们请求的这个美女图片的网页,我们上边给出的网址就是这个。我们从这个请求中拿取我们需要的请求头信息。
这里我只拿了Cookie和User-Agent。下方就是我们的请求头信息。
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0' , 'Cookie': 'cz_statistics_visitor=d8de5b1d-e51b-4986-734a-dee6c9baa136; Hm_lvt_aecc9715b0f5d5f7f34fba48a3c511d6=1715078740; Hm_lpvt_aecc9715b0f5d5f7f34fba48a3c511d6=1715078752; Hm_lvt_398913ed58c9e7dfe9695953fb7b6799=1715078772; _clck=wz5o14%7C2%7Cflk%7C0%7C1588; _clsk=1196i88%7C1715078773199%7C1%7C1%7Cu.clarity.ms%2Fcollect; ASP.NET_SessionId=a5jbwhq5z4sq25coftwlvkg4; Hm_lpvt_398913ed58c9e7dfe9695953fb7b6799=1715078929' }请求头的定制代码如下。注意我们的url是动态拼接的,需要根据传过来的页码来爬取第几页。
def create_request(page): url = f'https://aspx.sc.chinaz.com/query.aspx?keyword=%E7%BE%8E%E5%A5%B3%E5%9B%BE%E7%89%87&issale=&classID=11&navindex=0&page={page}' request = urllib.request.Request(url, headers=headers) return request

2.获取页面源码
把我们的请求头传进来,然后调用urllib中的request方法获取返回对象,然后通过第二行代码把网页内容读取出来。
def get_content(request): response = urllib.request.urlopen(request) content = response.read().decode('utf-8') return content

3.爬取我们需要的图片
想要拿到这些图片,我们就要知道这些图片的url到底是什么,我们接着去目标网页看源码,右键->检查->元素。
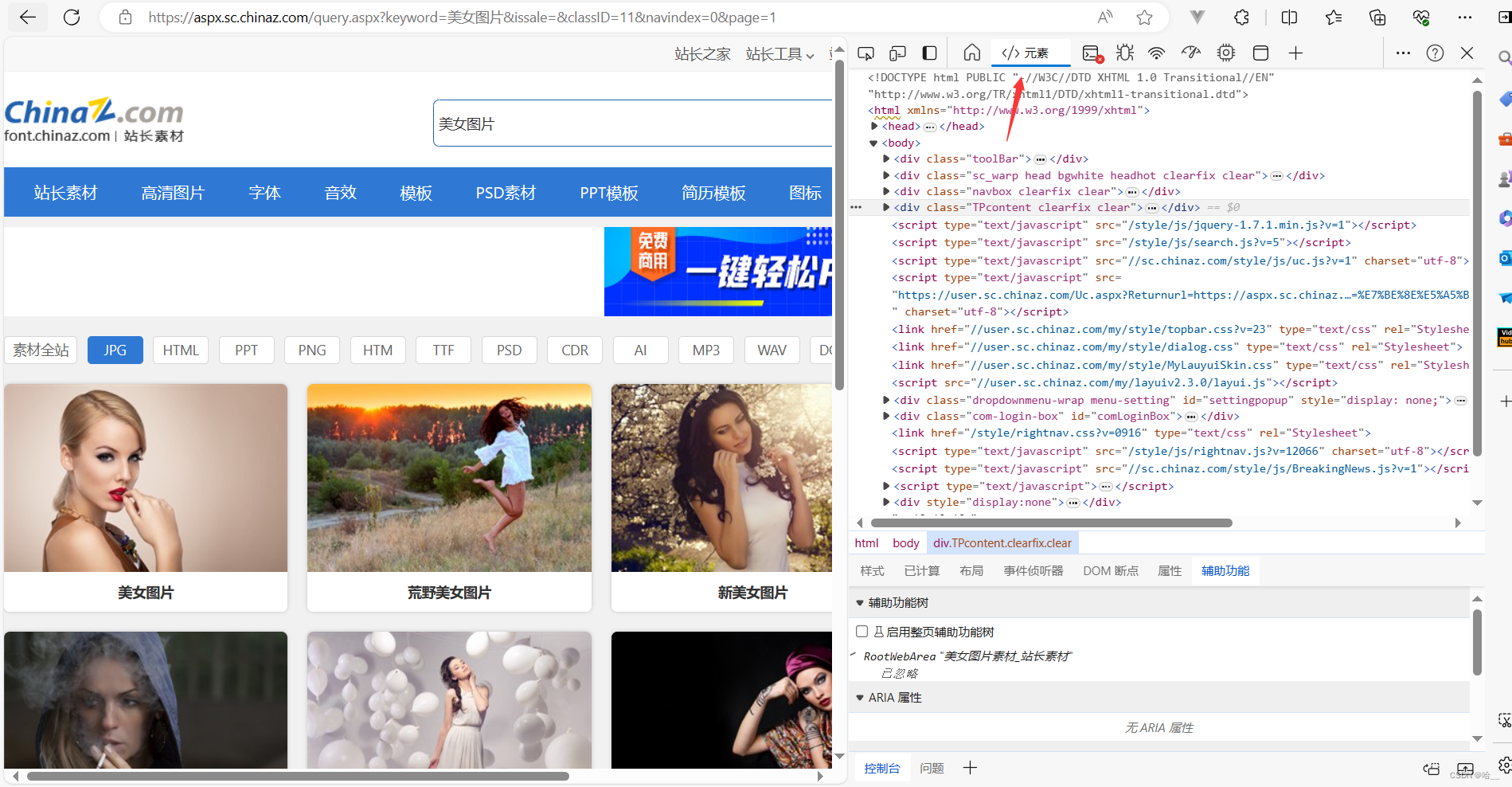
分析这个html代码的结构,找到我们图片是被哪个div包着的。
看到class为imgload的div下的结构了吗?这些机构就是我们一个一个的图片,我们想要获取的信息都在这里。一共有两个div,一个叫做im,另一个叫做heis,im当中保存着图片的地址,heis中保存着图片的名称,不信的话你可以把鼠标移动到im中的img标签的src上,看看能不能跳转到这个图片中。我们下载图片,就要使用xpath去把im中的img标签的路径描述出来。
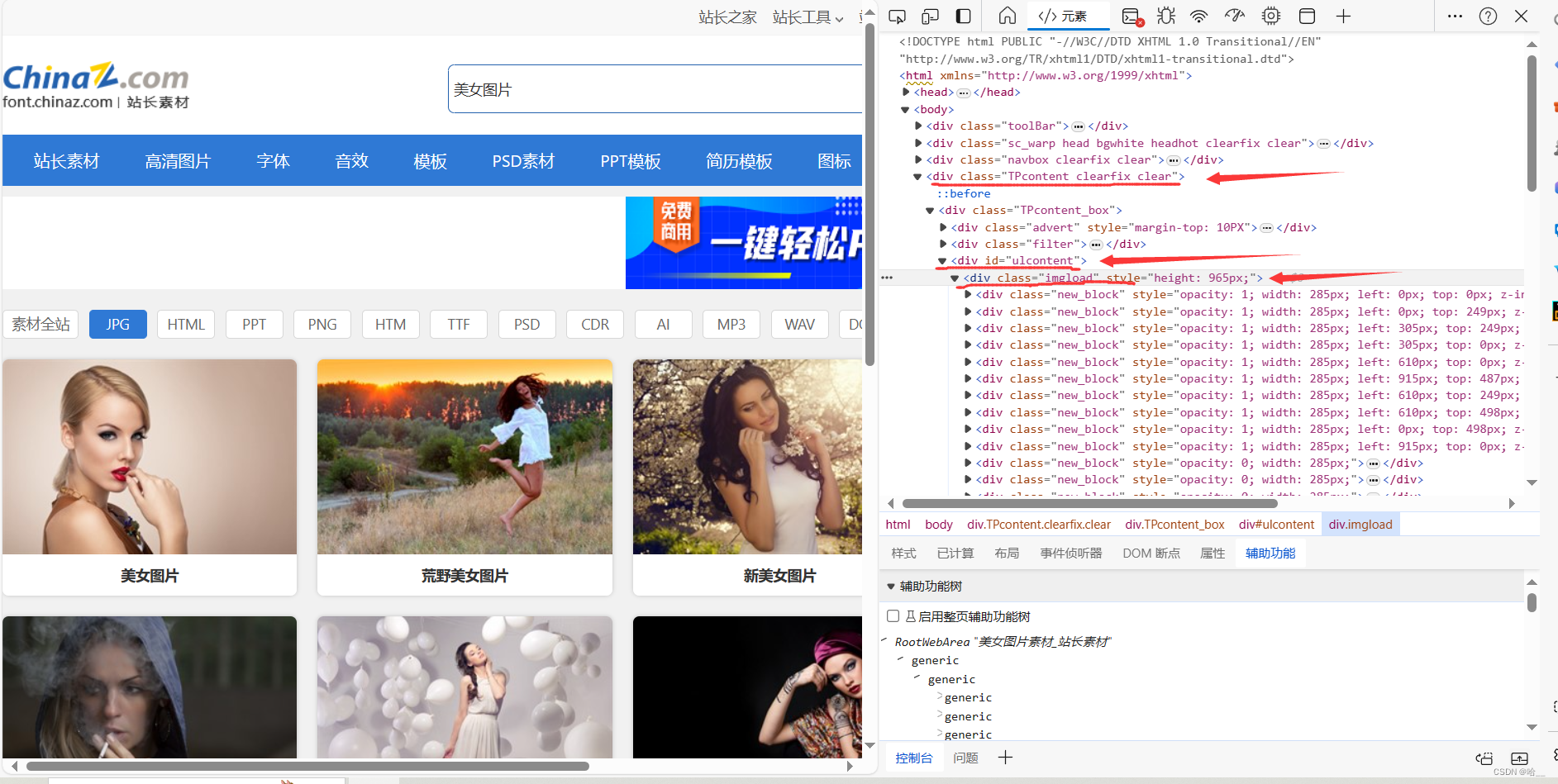
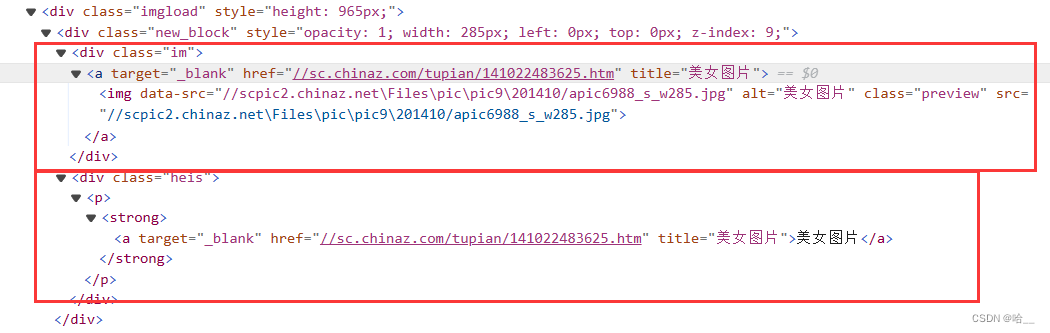
这里其实是有坑的,下方的div中的img根本没有src看到了吗?这里使用了懒加载的方式,你不进行滑动是根本不显示这个src的,所以我们要获取的不是src,而是data-src。

xpath代码。name_list就是获取所有图片的名称,src_list就是获取所有图片的地址。以图片地址为例。
- 我们寻找所有id值为“ulcontent”的div
- 然后找到这个div下所有class值为“im”的div
- 找class值为“im”的div下的a标签
- 然后找到a标签下的img标签
- 获取img标签的data-src属性的值。
name_list = tree.xpath('//div[@id="ulcontent"]//div[@class="heis"]//a/text()') src_list = tree.xpath('//div[@id="ulcontent"]//div[@class="im"]//a/img/@data-src')
有了xpath路径,我们就可以通过以下代码进行下载了。一定要注意斜杠的问题,我们爬下来的路径都是反斜杠,我们替换一下,同时添加一个https协议,就可以调用request库中的方法下载了。
for i in range(len(name_list)):
pic_url = "https:" + src_list[i]
pic_url = pic_url.replace('\\',"/")
pic_url = "https:" + pic_url
urllib.request.urlretrieve(url=pic_url,filename="./站长素材/"+name_list[i]+".jpg")一点点小问题
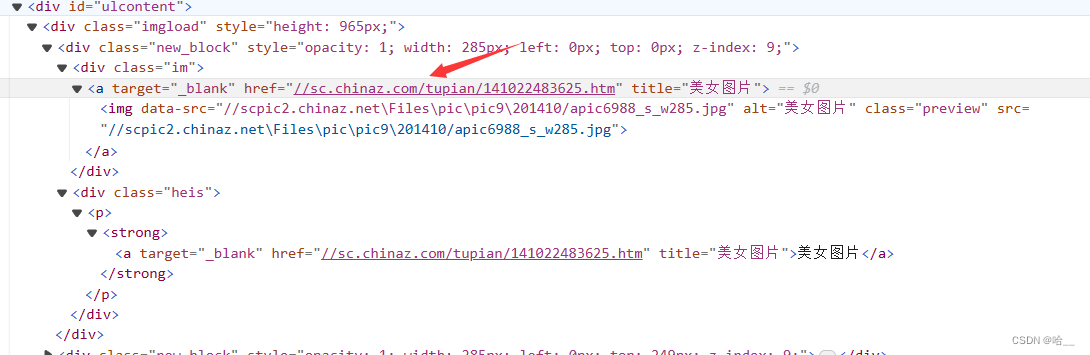
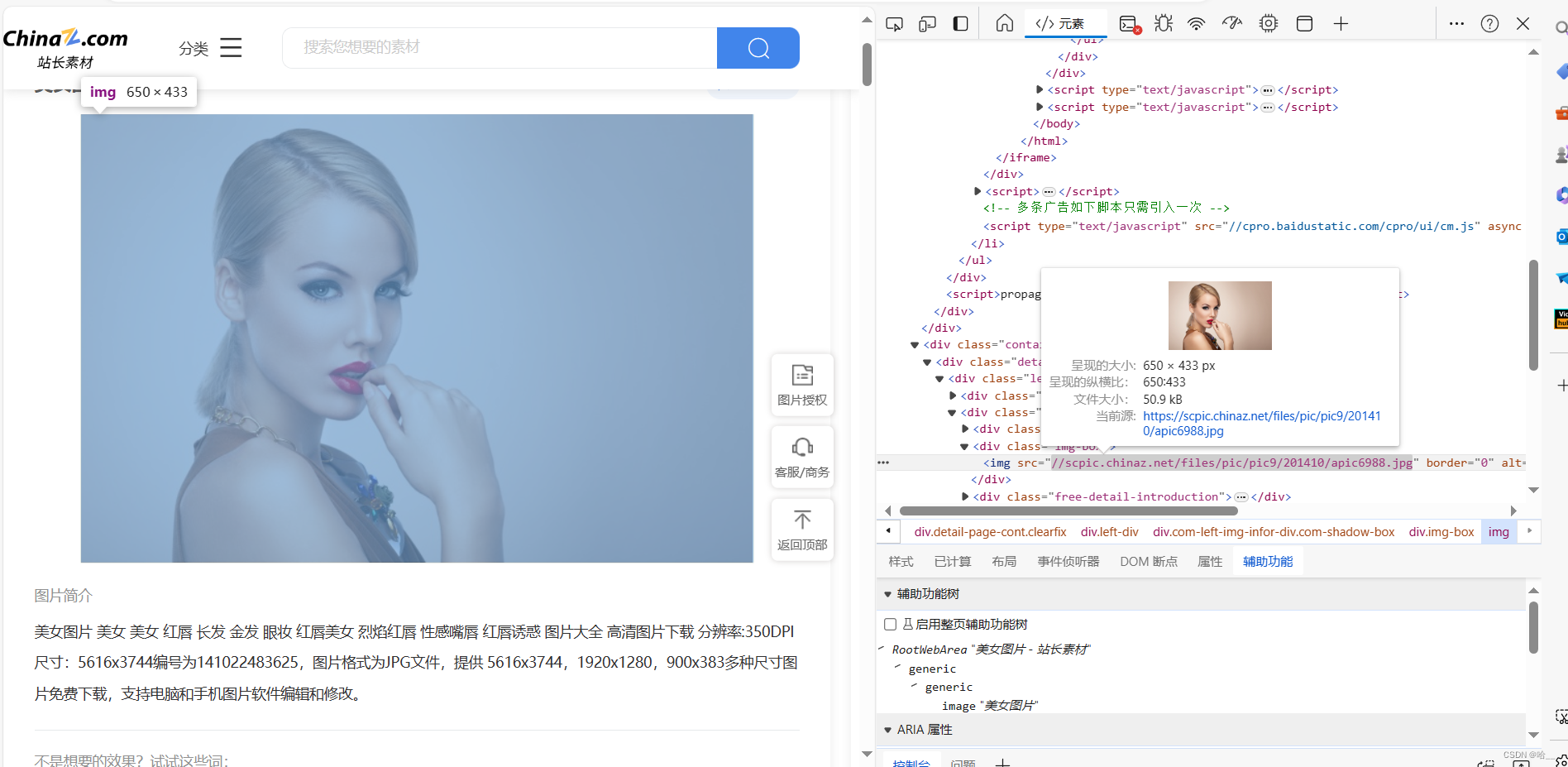
但是你可能会发现,我们爬取的都是缩略图,并不是高清图,我们的页面结构分析的没问题,但就是爬取的图片并不是真正的图片,真正的图片在这个网页中。
所以我们的代码要变一变,我们先把这个网页爬下来,然后再次通过request请求去访问这个网页,然后分析一下这个网页的结构,拿到这里的图片。
源码如下
import urllib.request
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
,
'Cookie': 'cz_statistics_visitor=d8de5b1d-e51b-4986-734a-dee6c9baa136; Hm_lvt_aecc9715b0f5d5f7f34fba48a3c511d6=1715078740; Hm_lpvt_aecc9715b0f5d5f7f34fba48a3c511d6=1715078752; Hm_lvt_398913ed58c9e7dfe9695953fb7b6799=1715078772; _clck=wz5o14%7C2%7Cflk%7C0%7C1588; _clsk=1196i88%7C1715078773199%7C1%7C1%7Cu.clarity.ms%2Fcollect; ASP.NET_SessionId=a5jbwhq5z4sq25coftwlvkg4; Hm_lpvt_398913ed58c9e7dfe9695953fb7b6799=1715078929'
}
def create_request(page):
url = f'https://aspx.sc.chinaz.com/query.aspx?keyword=%E7%BE%8E%E5%A5%B3%E5%9B%BE%E7%89%87&issale=&classID=11&navindex=0&page={page}'
request = urllib.request.Request(url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def download(html):
tree = etree.HTML(html)
name_list = tree.xpath('//div[@id="ulcontent"]//div[@class="heis"]//a/text()')
src_list = tree.xpath('//div[@id="ulcontent"]//div[@class="im"]//a/@href')
for i in range(len(name_list)):
pic_url = "https:" + src_list[i]
pic_url = pic_url.replace('\\',"/")
# 再次发送请求
request = urllib.request.Request(pic_url, headers=headers)
response = urllib.request.urlopen(request)
# 获得高清图片的页面源码
content = response.read().decode('utf-8')
tree2 = etree.HTML(content)
# 找到高清图片的地址
pic = tree2.xpath('//div[@class="container"]//div[@class="img-box"]/img/@src')[0]
pic = "https:" + pic
urllib.request.urlretrieve(url=pic,filename="./站长素材高清/"+name_list[i]+".jpg")
if __name__ == '__main__':
request = create_request('1')
html = get_content(request)
download(html)